
Цепи Маркова для чайников — это просто: примеры решения задач

Цепи Маркова применяются в о м ногих компаниях и организациях. С их помощью можно:
разработать маркетинговую стратегию,
предугадать результат каких-то действий,
разработать программное обеспечение, прогнозирующее случайное событие,
генерировать случайные числа,
генерировать случайный текст,
По сути, «марковские цепи» — это последовательность событий, при которой каждое последующее событие косвенно зависит от предыдущего. Таким образом, цепь Маркова формирует последовательность псевдослучайных событий. Именно для этой цели ее чаще всего и применяют.
Цепь Маркова
Цепь Маркова стала популярно й для генерации и предсказания случайностей, потому что она довольно проста в использовании. Она реализуется без применения статистических и математических алгоритмов. Ее использование при работе с большими данными и при изучении вероятного моделирования событий просто не заменимо.
Цепи Маркова на словах для чайников
Представим, что вы хотите спрогнозировать погоду на завтра. Вы точно понимаете, что за один день кардинально погода не меняется. На ее изменение влияет много факторов, например:
скорость и направление ветра,
движение атмосферных масс,
положение Луны относительно Земли,
Факторов , определяющих погоду , очень много, но они вам пока и не нужны, чтобы предсказать погоду на завтра. Вы понимаете, что , раз кардинально погода за один день не меняется, значит , она каким-то образом связана с сегодняшней погодой. Например, если сегодня дождь и температура около +10, тогда вероятность, что завтра будет солнечно и +30 , очень низкая. Скорее всего , завтра температура будет «больше или меньше» , а также будет идти или не идти дождь. Чтобы качественней прогнозировать погоду, вам нужно понаблюдать за ее зависимостями в течение нескольких лет.
Например, после наблюдений вы знаете, что если сегодня идет дождь, то вероятность солнечного дня составляет 1 из 4-х случаев, а вероятность пасмурного дня — 3 из 4-х. Поэтому на сегодня мы можем предположить , что завтра будет солнечно или пасмурно, но , скорее всего , пасмурно, так как так было в 3-х из 4-х случаев. По такому принципу можно прогнозировать погоду на несколько дней вперед. Это простой пример, в котором мы взяли только два вероятных события: солнечно либо пасмурно. На деле вероятных событий будет куда больше, например:
может быть опять дождь, а не просто пасмурно,
может полдня лить дождь, а полдня будет солнечно,
Чтобы прогнозировать погоду на несколько дней , нужно учесть еще несколько факторов. Например, если будет переход из дождливого дня в солнечный, тогда меняется система вероятностей. Когда будет солнечный день, тогда вероятность , что завтра опять будет солнце , будет 3 из 4-х, а вероятность дождливого дня будет 1 из 4-х.
Таким образом, цепь Маркова — это череда переходов между вероятными состояниями. У каждого вероятного состояния будет своя структура вероятностей последующих событий , по этому прогнозирование напрямую будет зависеть от того, какое вероятное событие главенствует. То ест ь от того , какой сегодня день: солнечный, дождливый, снежный, пасмурный, облачный и др, будет зависеть завтрашняя погода , п отому что у каждого вида дня есть собственный набор вероятной погоды завтрашнего дня.
Из всего сказанного получается, что цепь Маркова не создает точных долгосрочных стратегий, а напрямую зависит от «сегодняшнего» состояния объекта, для которого нужно вычислить вероятность. То есть в случае с погодой для более точного результата цепь Маркова лучше использовать к аждый день при прогнозе на следующий день.
Цепь Маркова: модель
С формальной точки зрения цепь Маркова представляет собой «автомат», который генерирует вероятности, в зависимости от входных данных. По факту цепь Маркова будет иметь вид матрицы, где будет прописана вероятность наступления следующего события, отталкиваясь от нынешнего.
Главное, что нужно знать: марковские цепи генерируют вероятность перехода из одного состояния, а не нескольких. То есть сегодня либо дождь, либо солнечно, а цепь Маркова не может учитывать , что солнце и дождь будут одновременно.
Давайте наш пример с погодой переведем в матрицу цепи Маркова. Выразим ее в форме таблицы, чтобы было понятнее:
Вправо вероятность состояний. Вниз нынешнее состояние погоды
Источник
Цепи Маркова и Пайтон — разбираемся в теории и собираем генератор текстов
Понимаем и создаём
Хорошие новости перед статьей: высоких математических скиллов для прочтения и (надеюсь!) понимания не требуется.
Дисклеймер: кодовая часть данной статьи, как и предыдущей, является адаптированным, дополненным и протестированным переводом. Я благодарна автору, потому что это один из первых моих опытов в коде, после которого меня поперло ещё больше. Надеюсь, что на вас моя адаптация подействует так же!
Итак, поехали!
Структура такая:
- Что такое цепь Маркова?
- Пример работы цепочки
- Матрица переходов
- Модель, основанная на Марковской цепи при помощи Пайтона — генерация текста на основе данных
Что такое цепь Маркова?
Цепь Маркова — инструмент из теории случайных процессов, состоящий из последовательности n количества состояний. Связи между узлами (значениями) цепочки при этом создаются, только если состояния стоят строго рядом друг с другом.
Держа в голове жирношрифтовое слово только, выведем свойство цепи Маркова:
Вероятность наступления некоторого нового состояния в цепочке зависит только от настоящего состояния и математически не учитывает опыт прошлых состояний => Марковская цепь — это цепь без памяти.
Иначе говоря, новое значение всегда пляшет от того, которое его непосредственно держит за ручку.
Пример работы цепочки
Как и автор статьи, из которой позаимствована кодовая реализация, возьмем рандомную последовательность слов.
Старт — искусственная — шуба — искусственная — еда — искусственная — паста — искусственная — шуба — искусственная — конец
Представим, что на самом деле это великолепный стих и нашей задачей является скопировать стиль автора. (Но делать так, конечно, неэтично)
Как решать?
Первое явное, что хочется сделать — посчитать частотность слов (если бы мы делали это с живым текстом, для начала стоило бы провести нормализацию — привести каждое слово к лемме (словарной форме)).
Старт == 1
Искусственная == 5
Шуба == 2
Паста == 1
Еда == 1
Конец == 1
Держа в голове, что у нас цепочка Маркова, мы можем построить распределение новых слов в зависимости от предыдущих графически:
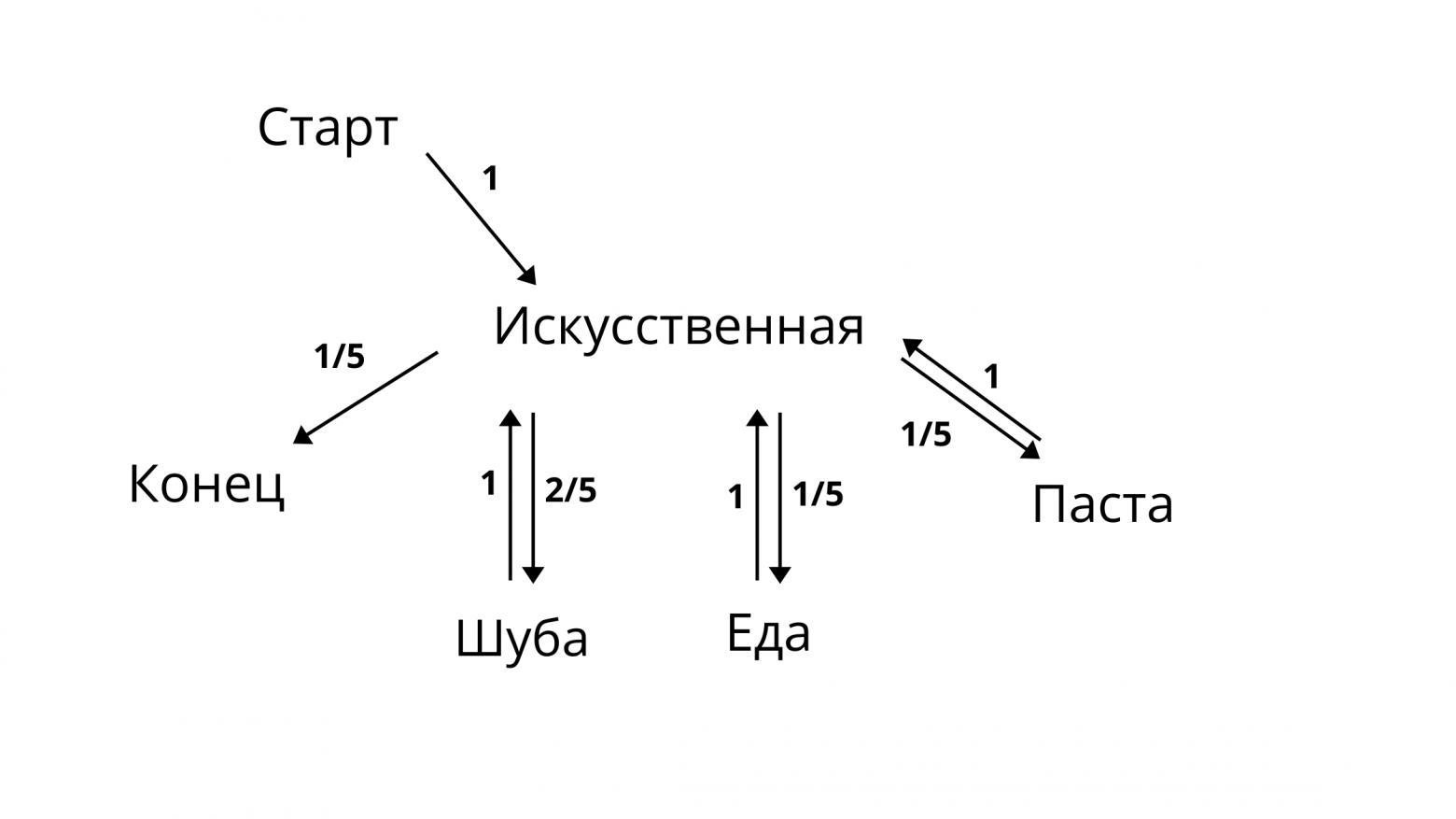
- состояние шубы, еды и пасты 100% за собой влекут состояние искусственная p = 1
- состояние “искусственная” равновероятно может привести к 4 состояниям, и вероятность прийти к состоянию искусственной шубы выше, чем к трём остальным
- состояние конца никуда не ведет
- состояние «старт» 100% влечет состояние «искусственная»
Выглядит прикольно и логично, но на этом визуальная красота не заканчивается! Мы также можем построить матрицу переходов, и на её основе аппелировать следующей математической справедливостью:

Что на русском означает «сумма ряда вероятностей для некоторого события k, зависимого от i == сумме всех значений вероятностей события k в зависимости от наступления состояния i, где событие k == m+1, а событие i == m (то есть событие k всегда на единицу отличается от i)».
Но для начала поймем, что такое матрица.
Матрица переходов
При работе с цепями Маркова мы имеем дело со стохастический матрицей переходов — совокупностью векторов, внутри которых значения отражают значения вероятностей между градациями.
Да, да, звучит так, как звучит.
Но выглядит не так страшно:
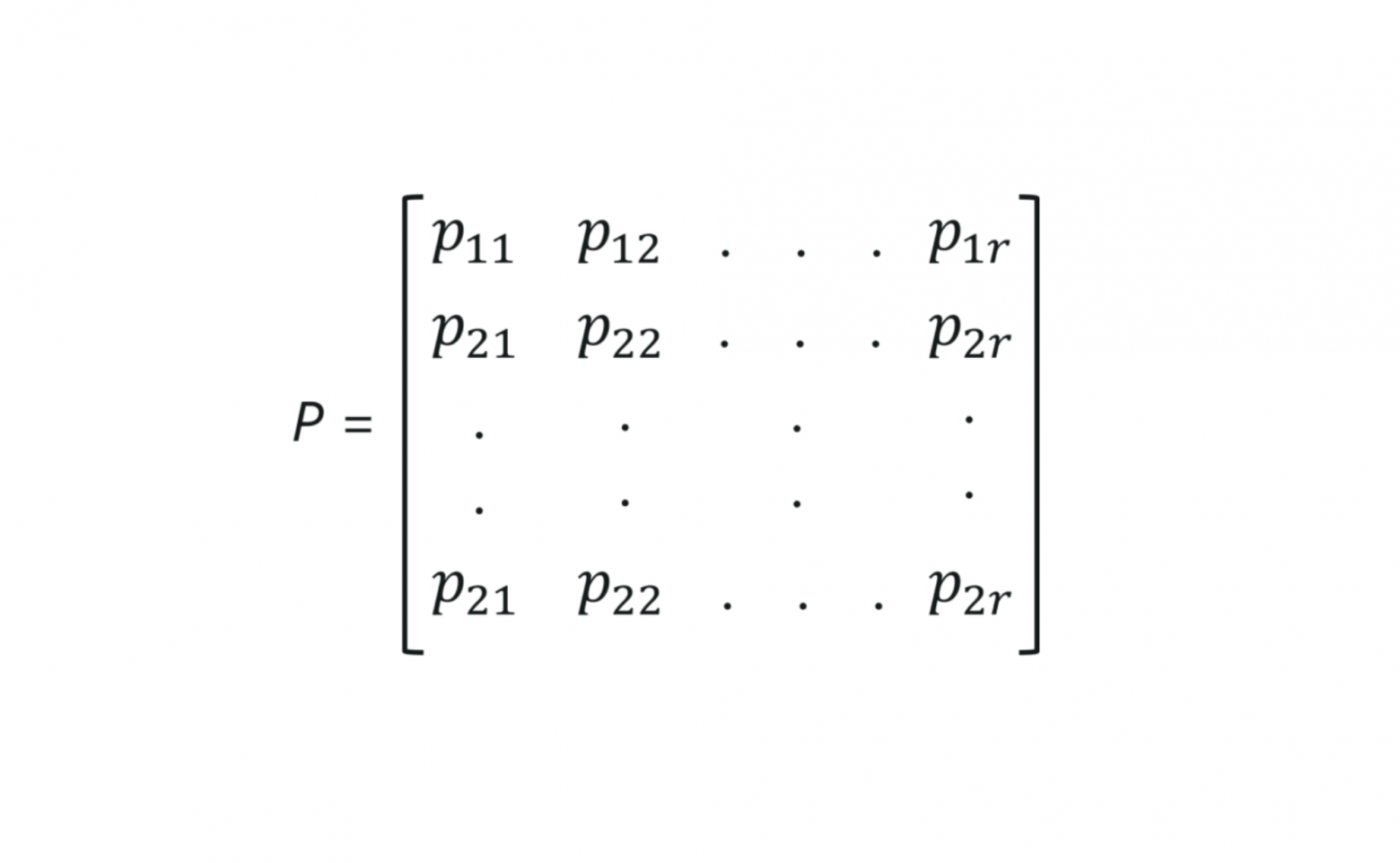
P — это обозначение матрицы. Значения на пересечении столбцов и строк здесь отражают вероятности переходов между состояниями.
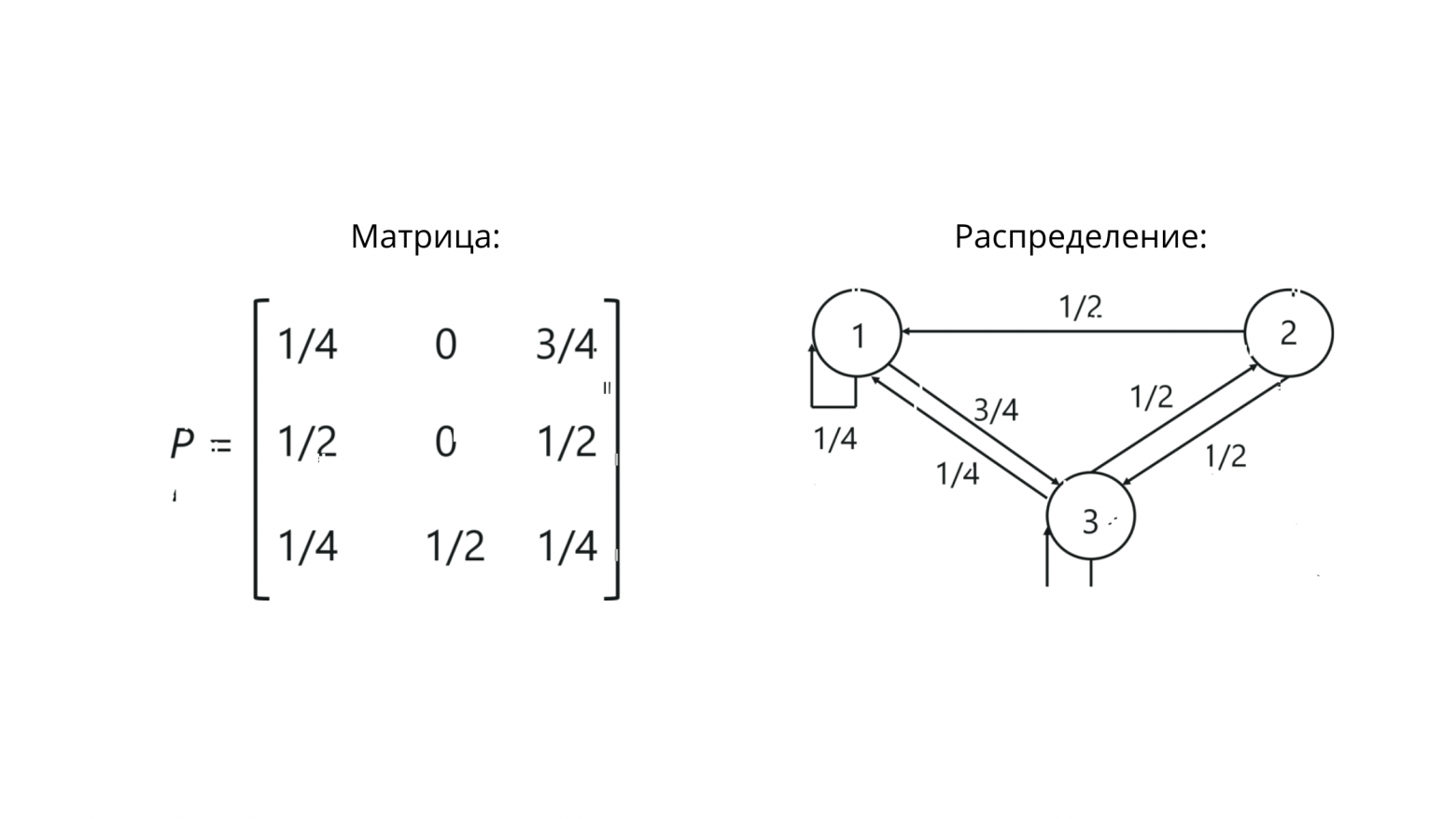
Для нашего примера это будет выглядеть как-то так:

Заметьте, что сумма значений в строке == 1. Это говорит о том, что мы правильно всё построили, ведь сумма значений в строке стохастический матрицы должна равняться единице.
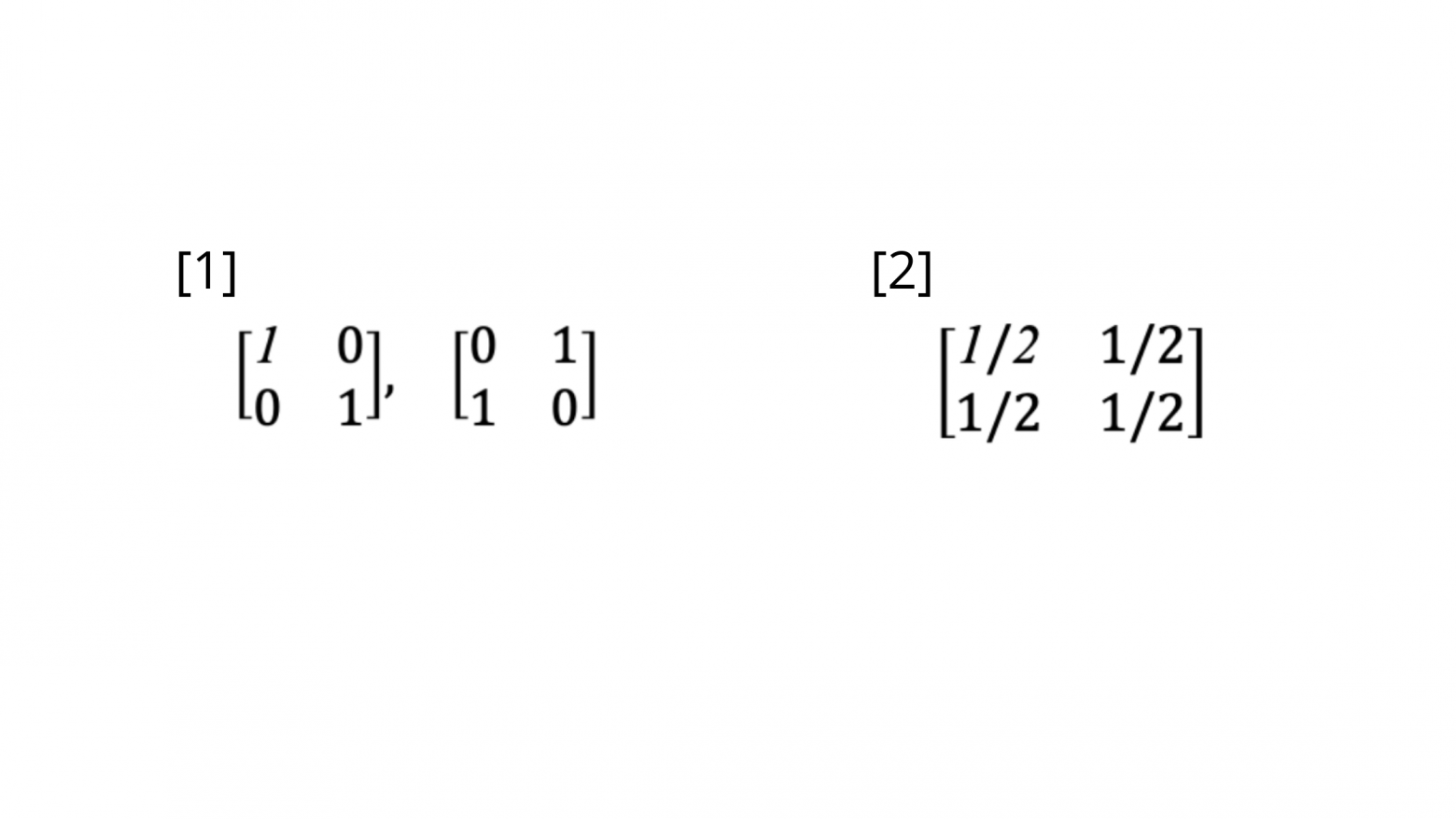
Голый пример без искусственных шуб и паст:
Ещё более голый пример — единичная матрица для:
- случая когда нельзя из А перейти обратно В, а из В — обратно в А[1]
- случая, когда переход из А в В обратно возможен[2]
Респекто. С теорией закончили.
Используем Пайтон.
Модель, основанная на Марковской цепи при помощи Пайтона — генерация текста на основе данных
Импортируем релевантный пакет для работы и достаём данные.
Не заостряйте внимание на структуре текста, но обратите внимание на кодировку utf8. Это важно для прочтения данных.
Создадим функцию для связки пар слов.
Главный нюанс функции в применении оператора yield(). Он помогает нам удовлетворить критерию цепочки Маркова — критерию хранения без памяти. Благодаря yield, наша функция будет создавать новые пары в процессе итераций(повторений), а не хранить все.
Тут может возникнуть непонимание, ведь одно слово может переходить в разные. Это мы решим, создав словарь для нашей функции.
- если у нас в словаре уже есть запись о первом слове в паре, функция добавляет следующее потенциальное значение в список.
- иначе: создаётся новая запись.
Шаг 5
Рандомно выберем первое слово и, чтобы слово было действительно случайным, зададим условие while при помощи строкового метода islower(), который удовлетворяет True в случае, когда в строке значения из букв нижнего регистра, допуская наличие цифр или символов.
При этом зададим количество слов 20.
Запустим нашу рандомную штуку!
Функция join() — функция для работы со строками. В скобках мы указали разделитель для значений в строке(пробел).
А текст… ну, звучит по-машинному и почти логично.
P.S. Как вы могли заметить, цепи Маркова удобны в лингвистике, но их применение выходит за рамки обработки естественного языка. Здесь и здесь вы можете ознакомиться с применением цепей в других задачах.
P.P.S. Если моя практика кода вышла непонятной для вас, прилагаю исходную статью. Обязательно примените код на практике — чувство, когда оно «побежало и сгенерировало» заряжает!
Жду ваших мнений и буду рада конструктивным замечаниям по статье!
Источник